Naming Best Practices
Ever had the case where you named some model quickly with test, test_1, another_test and then a week later don't know what it is used for?
How about asking colleagues from other teams about the models they created - chances are they are not named well and therefore nobody knows what this model is about after a month.
Good naming conventions usually take no extra effort, but help tremendously in productivity and smooth collaboration within & between teams down the line.
Naming best practices
The Y42 naming best practices are aligned with the Enterprise Data Warehouse & GIT best practices. For a deeper dive in why naming is so important visit this extended article.
The name should show very clearly what the data asset does.
A good naming always should be related to the content, and be as specific as possible.
For example: If you are calculating the revenue segmented by clients in February 2022, a good naming would be:
rev_by_clients_feb_22, or rev_by_clients_02_22
You might want to search by the asset name in the future and actually find it quick.
You can search for them in the overview menu of each product (Integrations, UI Model, SQl Model, Orchestration …etc ).

Or if you are not sure in which product this asset lives, you can search via the Global search (it will search throughout the while system):
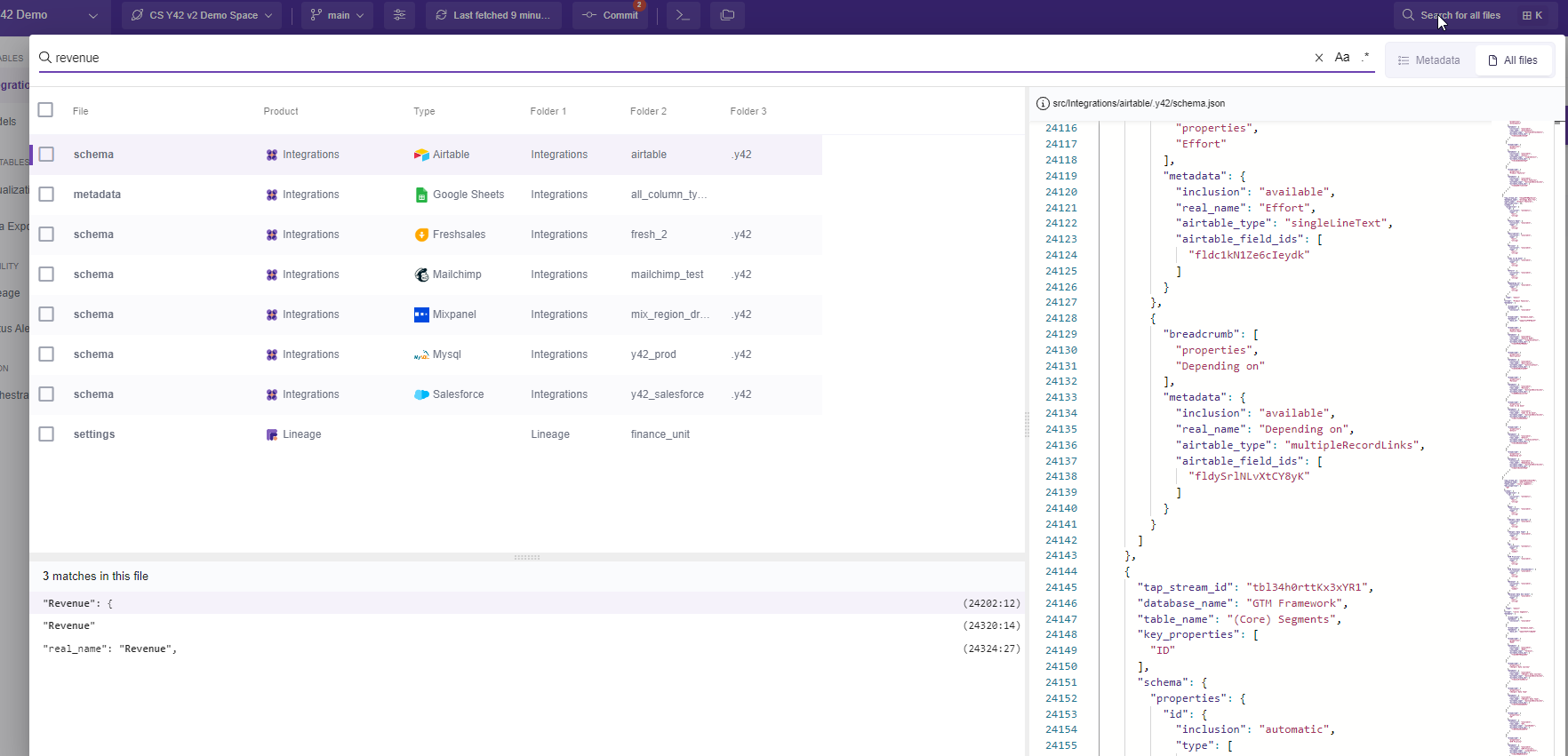
It's a good practice to set up some naming conventions within your team and iterate over it in your documentation.
Avoid similar names
The name should be distinguishable from other data assets of the same kind. Nothing is worse than similar names, for example:
revenue_by_client
revenue_by_clients
clients_revenues
You will get confused and forced to open all of them
The tables should be named as well.
A model can have many tables as an output. By default the table output name will be the same as the Model name followed by a counter.
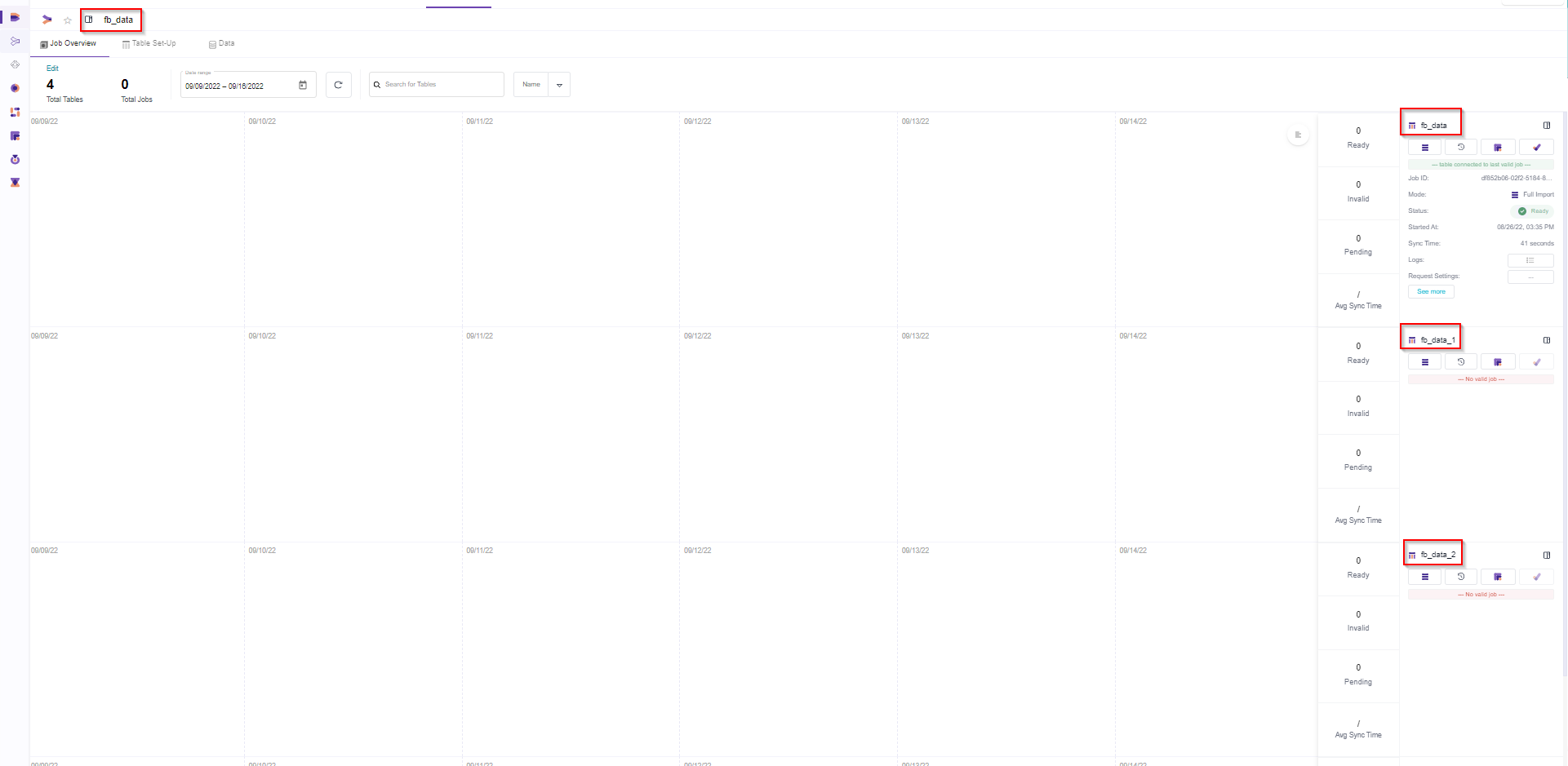
If you do not name them correctly you will find it hard to know what each table does, so you will have to jump to the model setup and investigate the flow. The other users will find this process even harder and time consuming.
That is why it is important to name also the Table names in UI-Model and SQL Model
Use underscore to separate the words
The best practice is to use underscore to separate words.
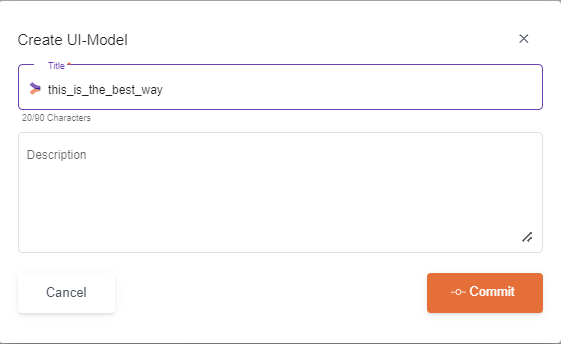
When using Space or + it will be converted automatically to underscore.
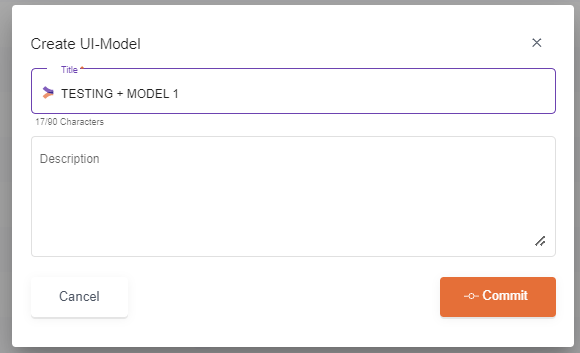
After committing it will look like this:

Use Lowercase if possible
When naming an asset there is no problem when using lowercase vs uppercase letters, however the output table name will by default be in lowercase.
While it is no problem naming an asset with lowercase or uppercase, we strongly recommend using lowercase always.
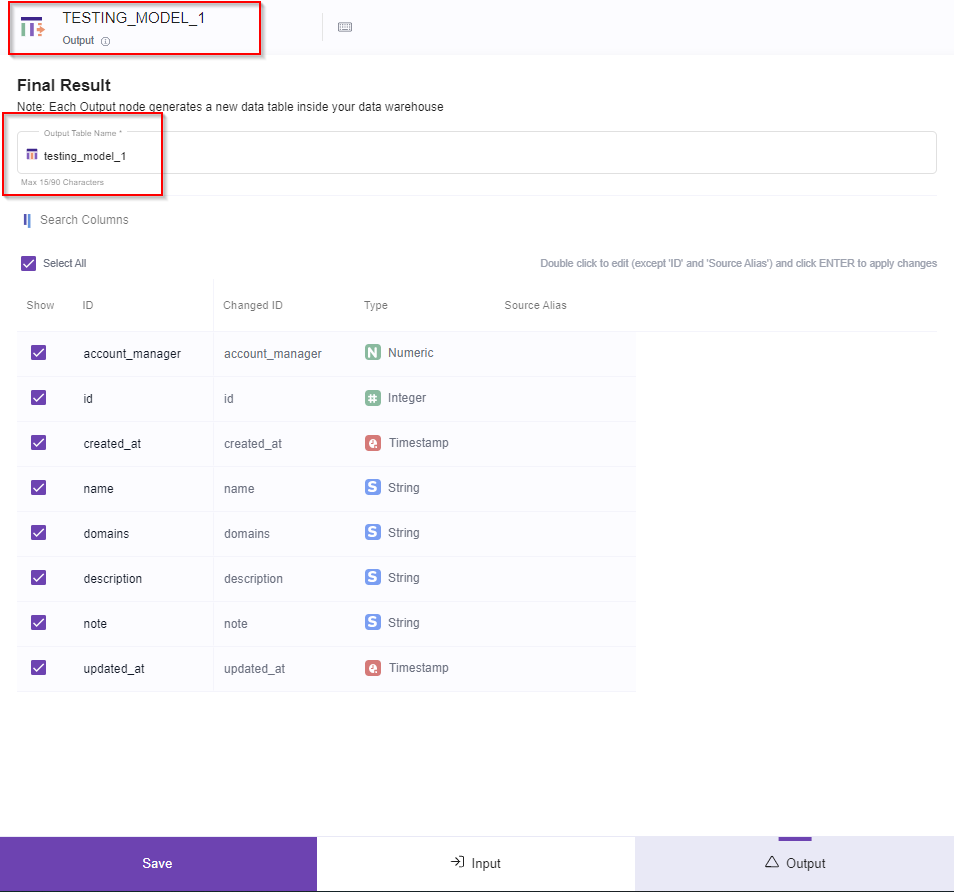
It is best practice to change the output table name, specially if you have multiple output tables inside one Model.
Note: you can always change the output table name but uppercase and special characters ate not accepted.

Prefer a shorter name over a longer one if it reveals intent clearly.
Use a shorter name only if it reveals the intent clearly.
For example get_clients_data is better than retrieve_the_clients_data.
It is best practice to not use numbers or special character as a first character in the model name
While it will be accepted and will not cause problems, it will throw an error when you try to rename the table output name

The description should be filled.
Adding a description can give the necessary hints to access the Model with security.
You can access each Model, or any asset by:
1- Clicking the open asset, which is located anywhere near the title.
2- Go to Metadata
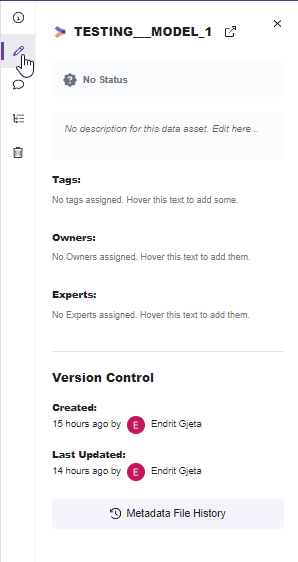
3- Add the description
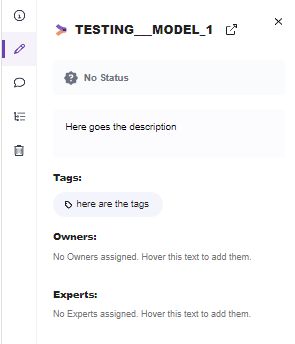
Note: Here you can also add the status, tags, owners (users), experts (users)
Use tags as the better alternative for folders.
Tags help tremendously in filtering and searching for data assets. You should therefore use them extensively. At the same time, having a system within your team will ensure that the same tag is not used for different purposes.
By clicking the + sign you can easily add tags, in each overview menu of an asset.

This can help visually find the Data Exports or you might as well filter them by clicking in the tags column filter.
You can filter any time also from the Open asset menu, by going to metadata.
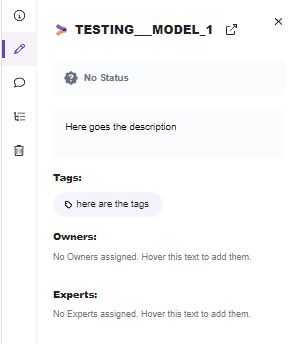
Tags can be used to distinguish between stage (e.g. source, mart, analytics), teams, data source, etc.
Make sure to align with your team on an initial set of tags and iterate and add as needed.
Use views to distinguish between teams, stage of the data pipeline, data sources, etc.
This is a very Handy helper so you can jump directly to some preset filters like:
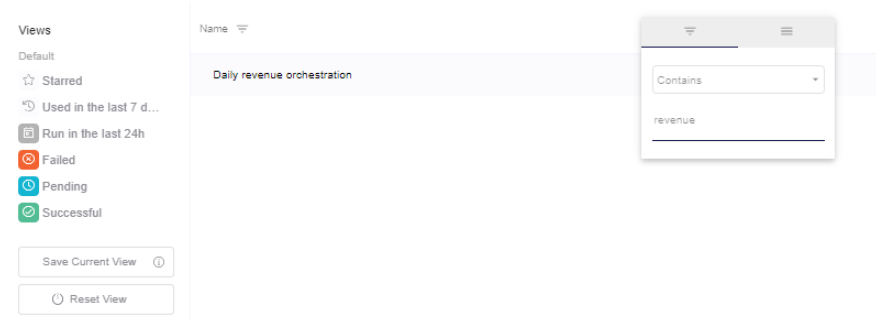
But what is even more powerful is the fact that you might create your personalized views, by simply following these steps:
I.- Filter or Order by any column.
Here for example I will filter with the name revenue:
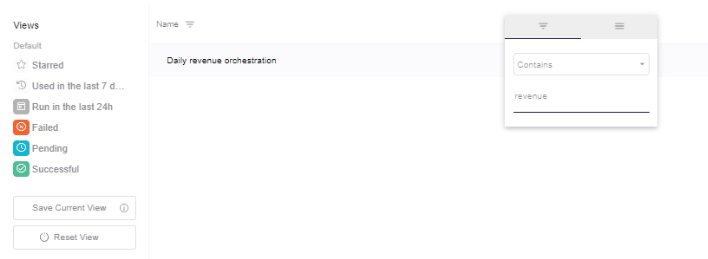
II. - Click "Save Current View" button.
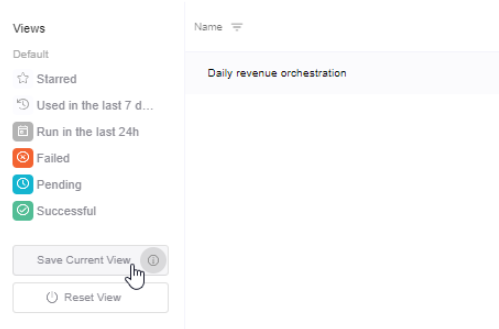
III. - Add the View a descriptive name and/or icon &color and click Save.
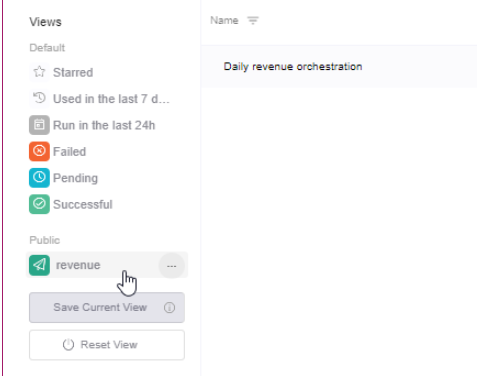
IV- If you want to jump back to the default view of all the Data Exports, simply click the "Reset View" button.
Updated almost 4 years ago