How to create a Data Pipeline fast
If your data changes, like for example your integration might be connected to PayPal, and you always make new sales, which means new rows will be added in your integrations, and on top of that you run your analytics using probably a model or visualization layer then you definitely need to run an orchestration in order to keep working with updated data.
Below you will find the steps of how to create a data pipeline fast using SQL model and Orchestration.
I. Create a SQL Model based on existing tables.
What is SQL Model?
SQL Model is an advanced way that allows users who know the basics of SQL to apply direct queries to the selected data stack, like they would do in their Database in order to transform and retrieve (and save) the desired output table.
Adding a SQL-Model
Basically everything a user can do with UI-Model through nodes an advanced user can do with SQL model in a faster way.
The way it works is that when the user created the query and commits the changes, a new table/s is created on top of the one the user is working on. Later the user can change it or do whatever he/she wants.
Every time you need to update the new data table you need to either commit the SQL-Model or run an orchestration to trigger it in a scheduled manner.
To sum up all the steps of creating a working SQL-Model you should:
1- Visit the Model overview Menu and click the SQL-Models sub category. Here all the SQL models appear.
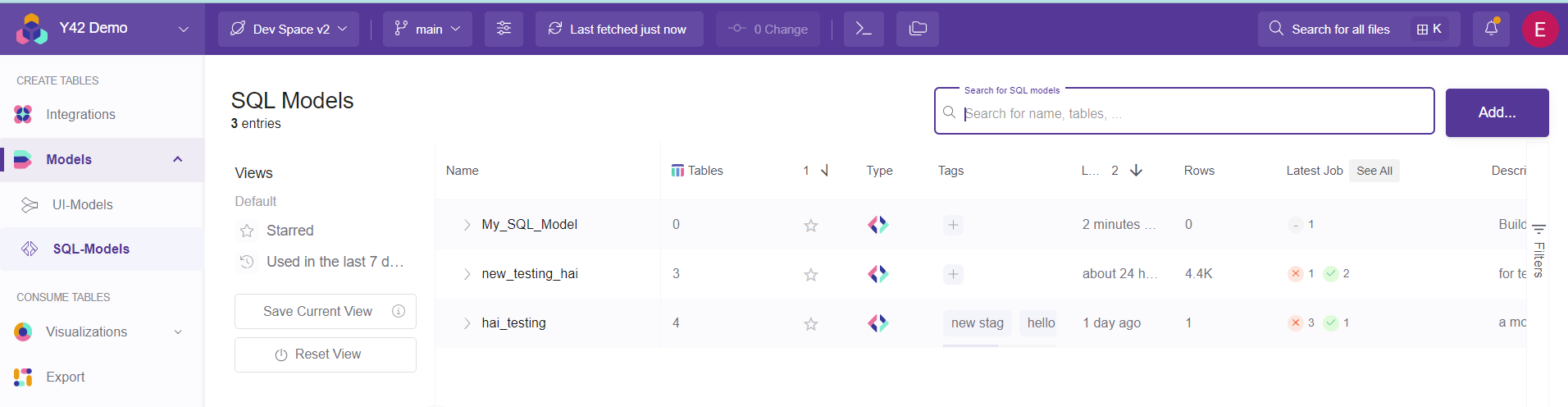
2- Add a new model (or open an existing one if you want to do changes).
3- Enter the name of the new model and submit.
4- Write the query.
The fastest way of writing a query is by clicking the "Toggle Schema Explorer" button. Here you can view all the table sources available for use. They appear like a tree, and by selecting the specific source table you can view all the table columns.
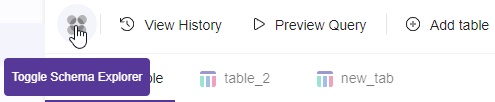
You can immediately generate a select statement with all the columns if you click the generate query button when you hover to a specific table you want to work on. You can start working right away with just one click.
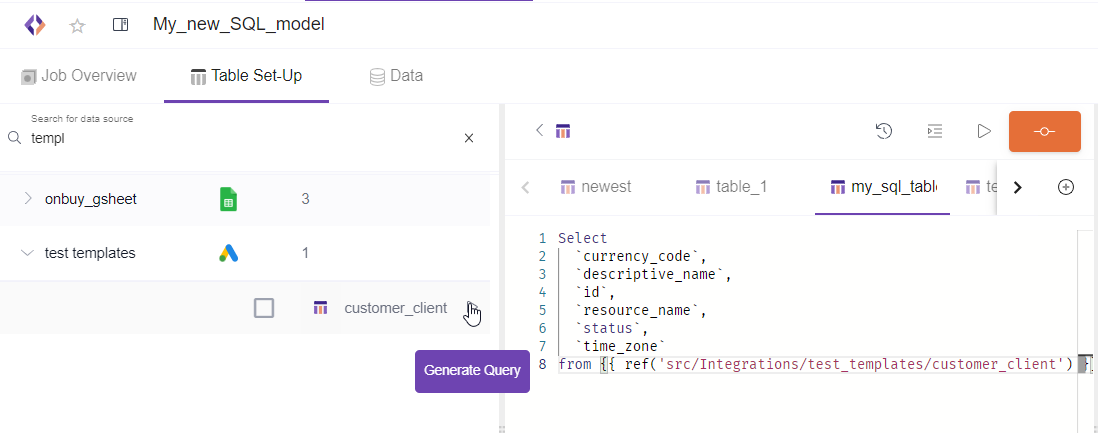
You can find more tips and suggestions in this extended article.
Data Preview. After clicking "data preview", the results table will be displayed in the right part of the screen.
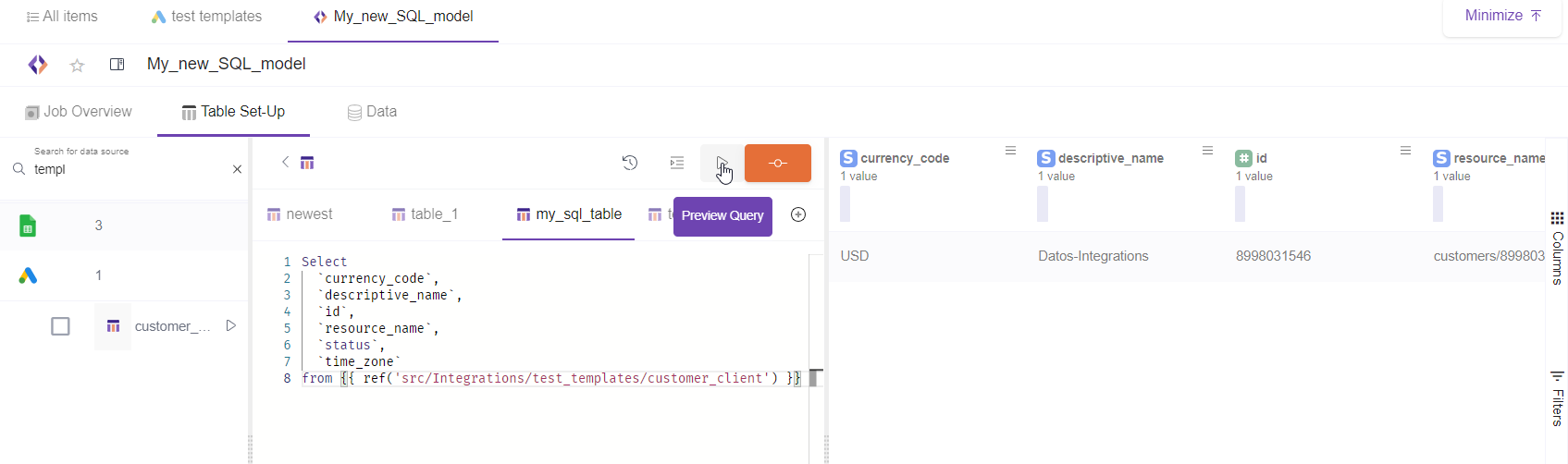
5- Commit and trigger table jobs.
Once you made the changes you wanted to click commit in order to save your changes into the output data.

Note: After the data are committed the button will become non-clickable until new changes happen inside the board.
Important note: After this commit a new table is created. This table can be reused at any time by a new model, export, dashboard or orchestration.
Every time you need to update the new data table you need to either commit the SQl-Model or run an orchestration to trigger it in a scheduled manner.
In order to view the new data table created you simply need to go to the data section.
A more detailed article on the data section can be found in this article.
II. Use the added SQL model into an Orchestration
What is an Orchestration
Orchestration is a powerful tool that Y42 offers to keep your data fresh as a living organism. What it does is very straight forward, it automates the triggering process by following your logic sequence and your schedule. You just need to set it once and it will proceed infinitely.
Adding an Orchestration
You should keep in mind that when you trigger an orchestration the update process of the selected tables starts from left to right of the connections you made using nodes.
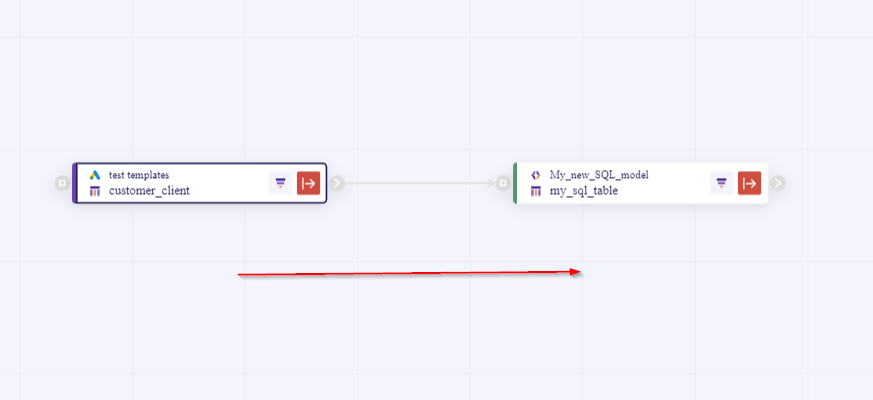
1. Visit the Orchestrate overview Menu.
Here all the orchestrations appear. Look at this article to better discover all the Orchestration Overview Menu functionalities.
2. Add an Orchestration (or open an existing one if you want to do changes).
Click the Add… button.
3. Enter the name of the new orchestration and submit.
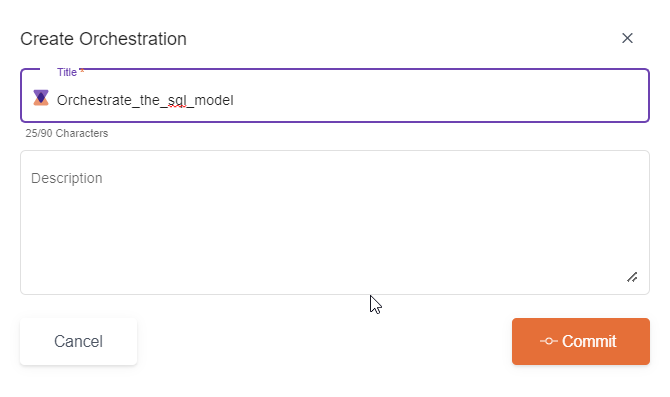
4. Click Add Nodes to your Orchestration.
Now you are inside your newly created orchestration, by default you enter into the Orchestration Setup. If you want to know more about the Orchestration Setup component then visit this article.
5. Select the data to add in the Canvas.
It is time to pick the data and the logic to always have the updated dataset whenever you need it.
Follow these steps as per the image counter:
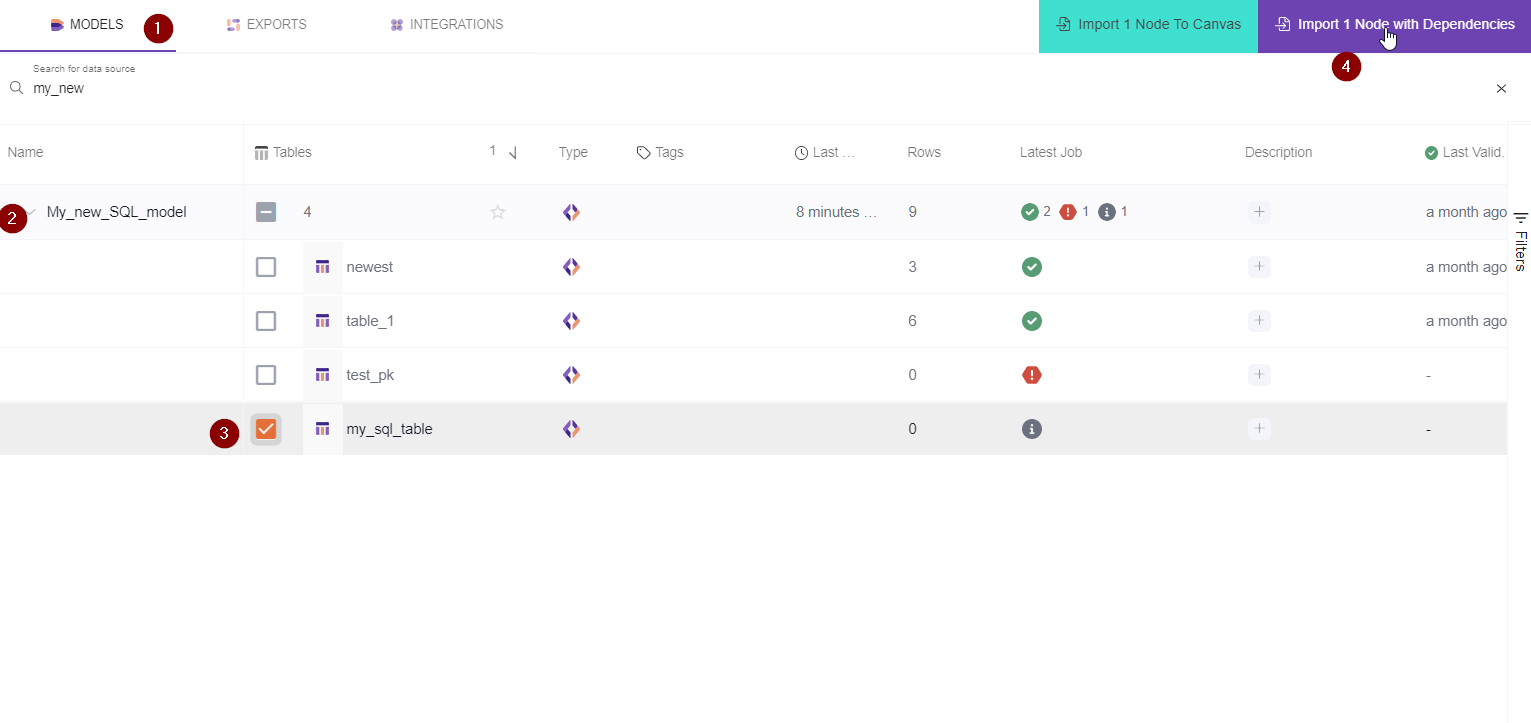
1- Select the data Nodes by filtering based on the following logic:

By clicking the buttons you filter by:
- Integrations - lists all Integrations
- Models - lists all models
- Exports - lists all exports
Note: If you want to auto-generate based on dependencies look at the step 4 below.
2- Expand the record you want to import.
3- Select the table/s to import in the Canvas.
4- Import to canvas by importing single node or node with dependencies.
a) If you want to auto-generate based on dependencies click the import node with dependencies button:

This will Auto Generate a Model or an Export into the canvas. For example: After you select an export it will also automatically select the integrations and/or models dependencies this automation is built on.
b) If you want to manually design the orchestration logic then click "Import 1 Node to Canvas"

This button will only generate the selected node into the Canvas, without its relational dependencies.
In our case we will import with dependencies:
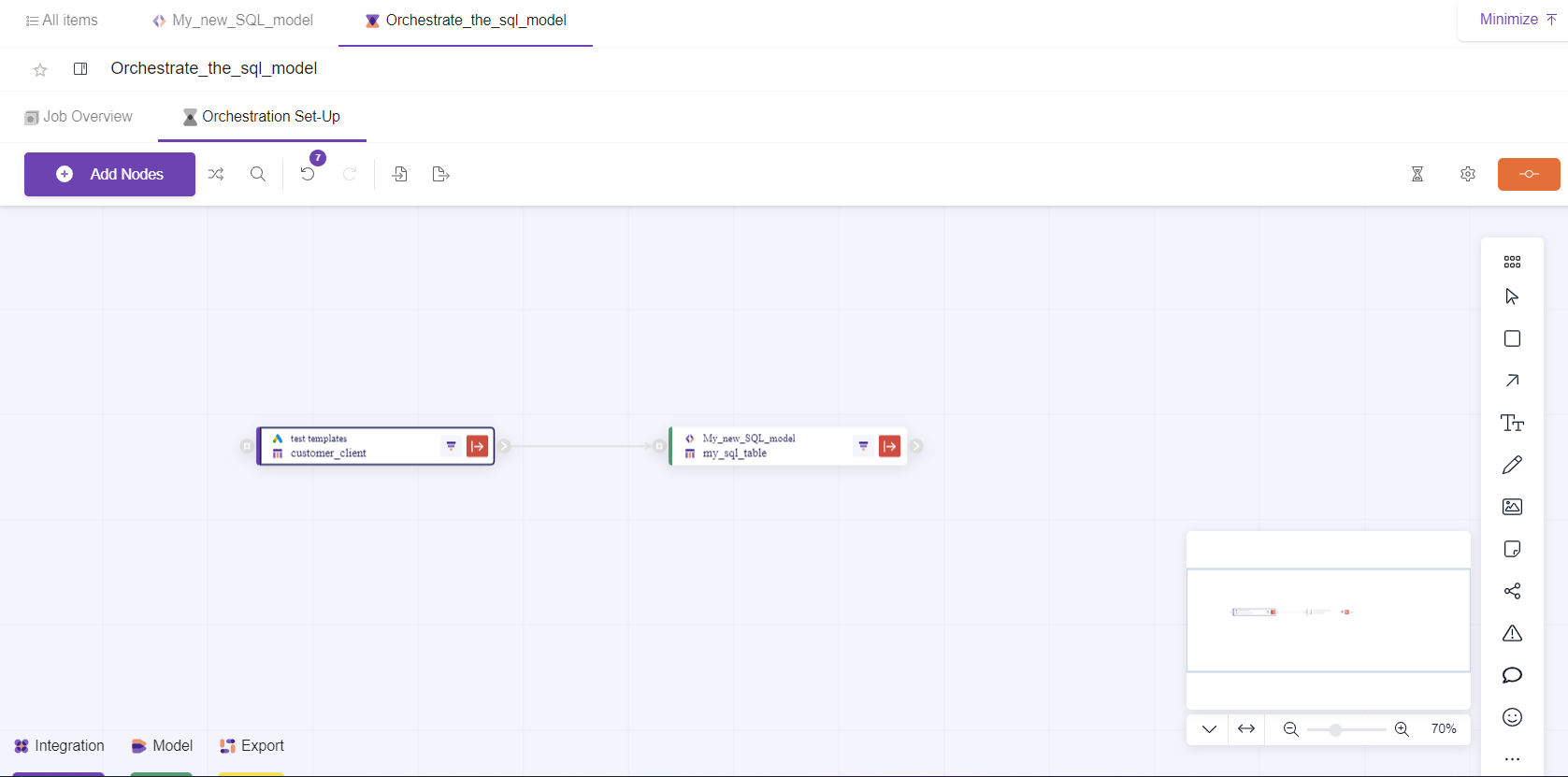
6- Work with the Canvas board
In case you wanted to do the logic yourself manually you can import to canvas any kind of tables which will appear as nodes and connect them manually with each other by drag and drop the end of one node with the beginning of the other.
You might also want to use Collaborative Tools to add notes, shapes, helper nodes etc.
Discover more on Collaborative tools in this article.
You might also filter the nodes based on their typology (Integration, Model, Export) in the bottom-left of the Canvas.
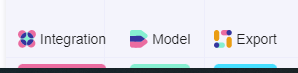
Important consideration: Incremental Vs Full Import switch.
For each node you can select if you want to do an incremental import or a full import.
In a nutshell the difference between an incremental and full import is that the incremental import is more fast and lightweight because it simply adds new rows to the table, whereas the full import imports the whole data table from the beginning.
7- Commit the Orchestration.
Important: In order to trigger the orchestration logic that you put in the canvas you need to commit it. Otherwise the last commit will be applicable in your trigger schedule, and your changes will not have the desired impact.
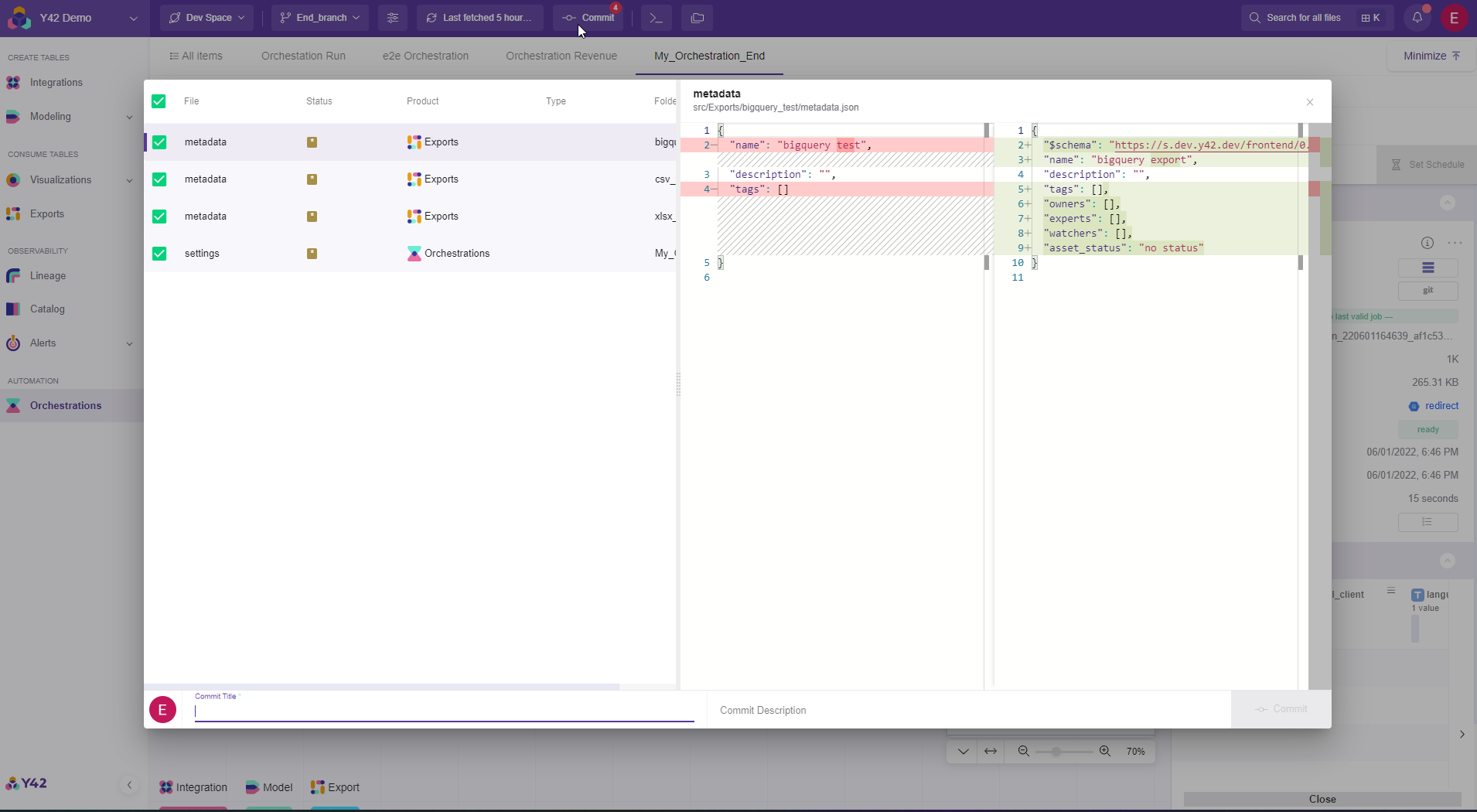
In order to commit you simply need to click the commit button and after that a window pops-out, the you need to add a commit title and optionally a description. Then again click commit.
8. Go to Overview section menu of the Orchestration.
In order to Trigger/ Schedule this orchestration you need to go the the Overview section.
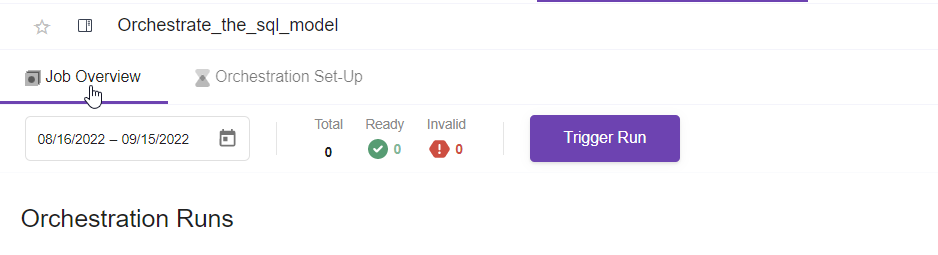
9. Trigger now or Set the Schedule
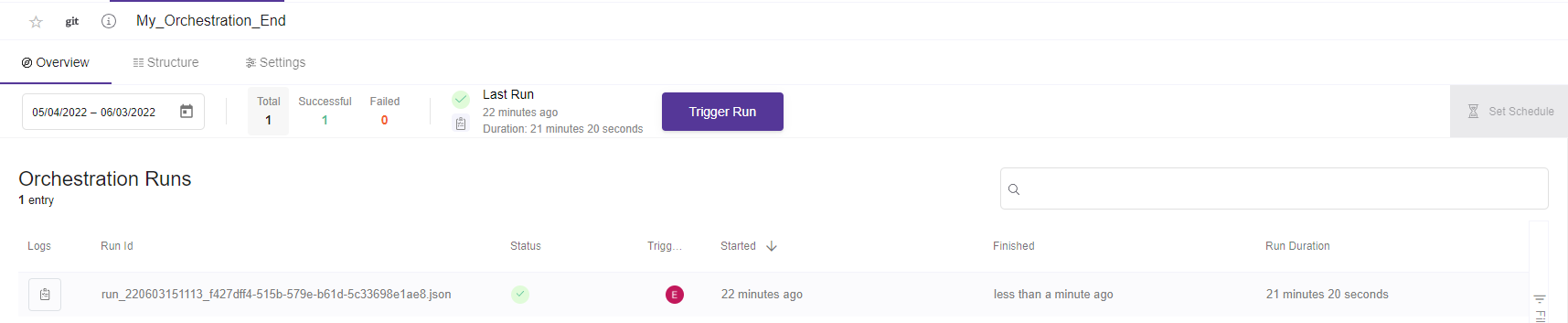
- Trigger now. When you click trigger now it will run the orchestration flow, by creating immediately a job which will have one of the 3 statuses (Success, Failure, Pending).
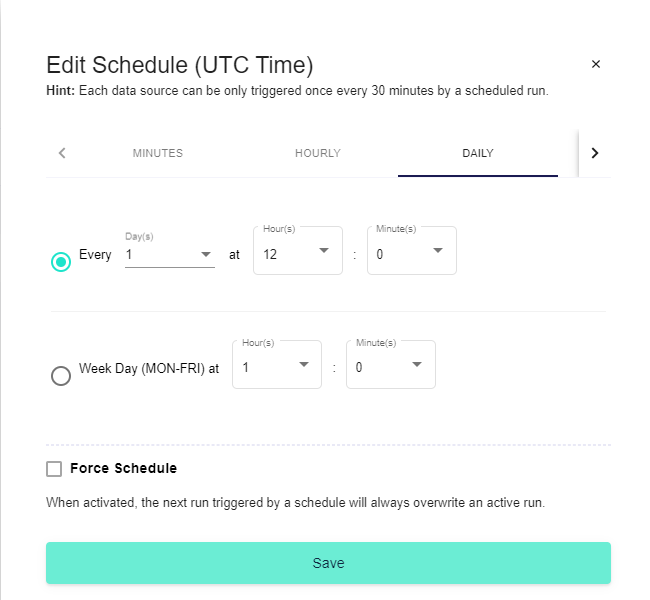
- Set Schedule. Schedule is the component that makes the flow recurrent.
You can set the schedule to run grammatically according to your needs: In Minutes, Hourly, Daily, Weekly, Monthly and Yearly bases.
A job will be created in each run, which will have one of the 3 statuses (Success, Failure, Pending).
Note: If you want to force schedule you can do so by checking the Force Schedule checkbox, but here you need to be careful because the next scheduled run it will overwrite the job in progress in case it has not finished yet. If you leave this checkbox as by default not checked the next run will wait for the actual run to finish.
Note: In order to Set a schedule you need to be in the main branch.
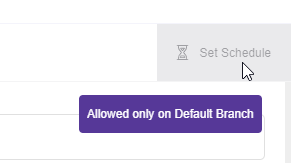
Important note: If you have opened a Branch you need to:
1- commit all the changes
2- go to the main branch.
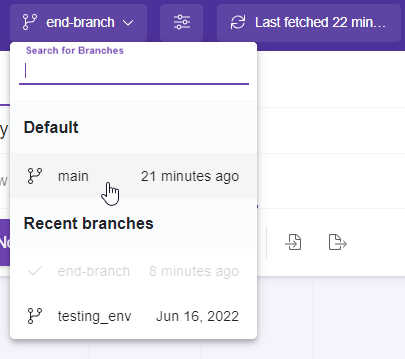
3- Select merge into current branch
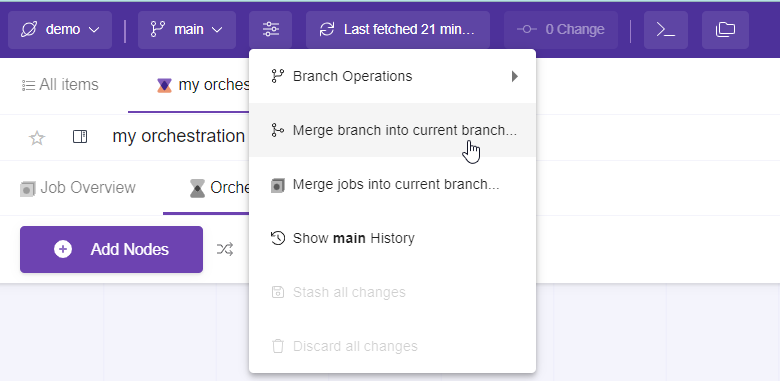
4- Go to the orchestration and Set the Schedule.
You can monitor the jobs run in the orchestration Job overview section
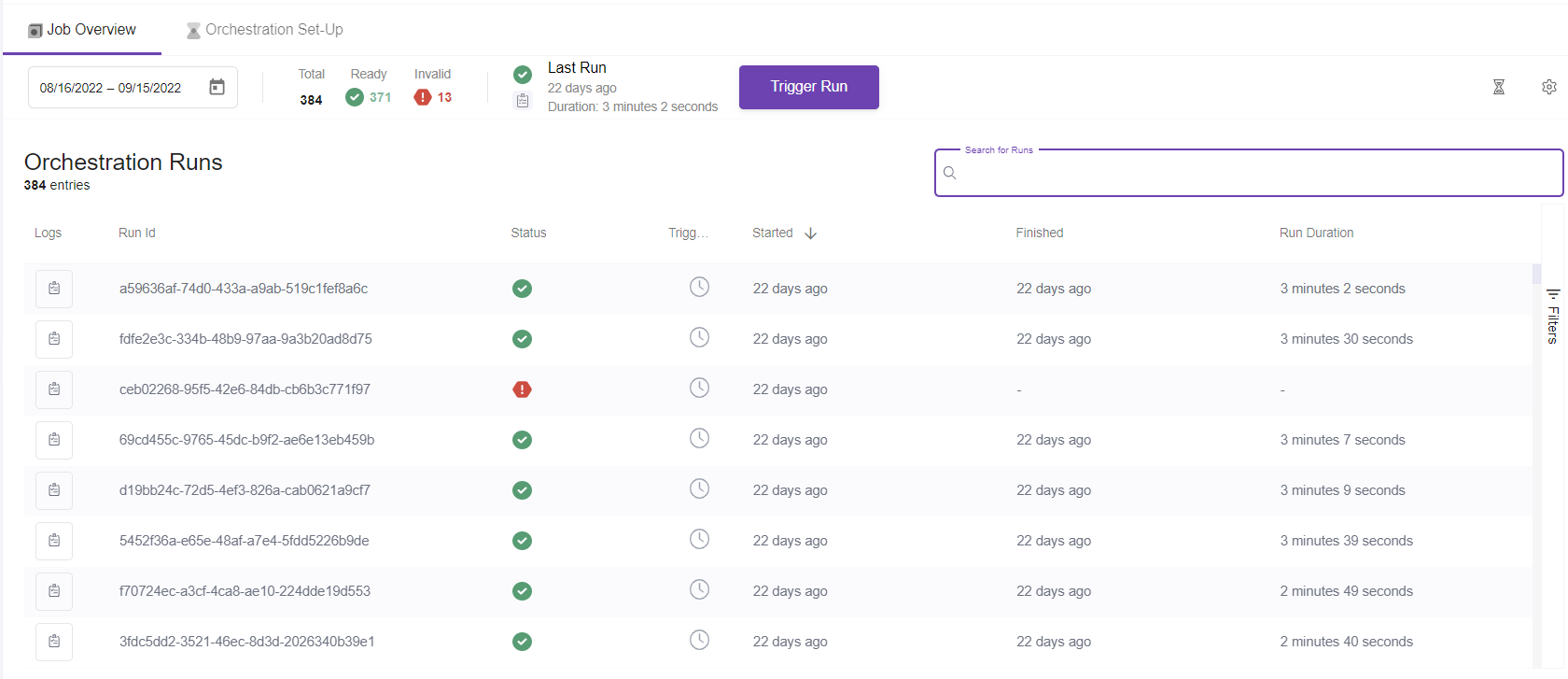
Congratulations!!! Now you have created a data pipeline which runs on its own.
Updated over 3 years ago