Introduction to data lineage
Overview of the goals and capabilities of data lineage in Y42
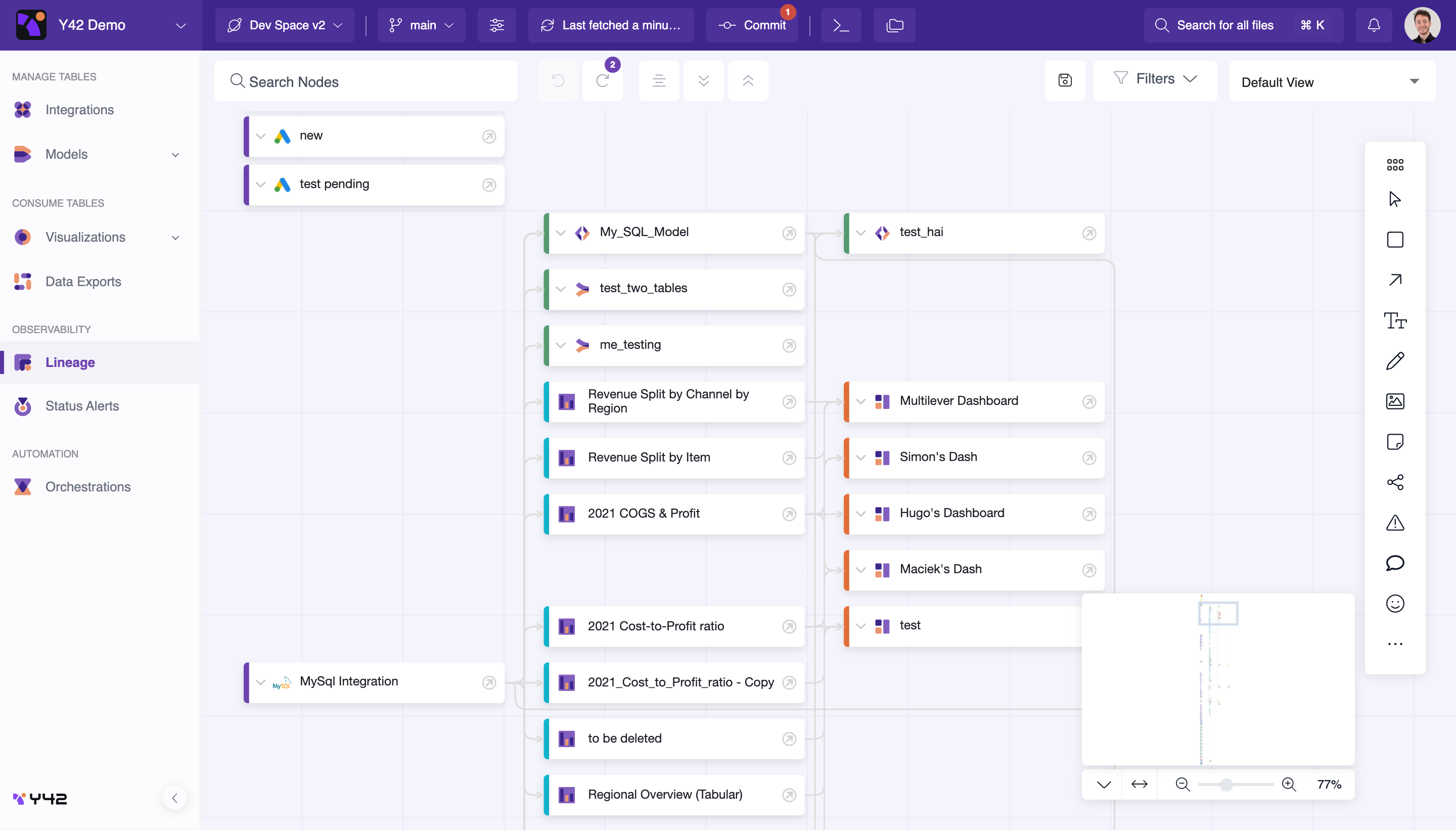
What is data lineage in Y42?
Data Lineage provides a holistic overview of your data flows in the Y42 platform. While other product modules give a zoomed-in view of specific parts of your data pipeline, the lineage helps you achieve a “Big picture” understanding of your solutions. Following the lineage graph, you will understand the origin of data assets, the transformations they undergo, and what they are used for.
Two relevant use cases are:
- Easing high-level understanding and documentation of data pipelines
- Improving traceability of assets impacted by errors and changes in pipelines
The latest version of our platform allows persisting lineage canvases: You can save different annotated versions of the lineage, together with a set of filters and highlights that you decide to apply to them.
Why should you use data lineage?
- As the complexity of your pipelines increases, it's easy to lose awareness of how the whole puzzle fits together.
- Gives you a high-level overview when building solutions
- Helps document your pipelines, making the onboarding of new contributors easier
- Helps trace back error sources and tracing down their impact on the pipeline
- Helps identify unused data assets
- Helps build business trust by pointing assets back to their sources and indicating the transformations they have undergone
How is data lineage generated in Y42?
In our platform, you build a solution using a combination of no-code and code interfaces, and we generate the lineage from the equivalent SQL code. Therefore, you can expect assets to appear in the lineage as soon as you configure them, independently of whether these materialized in your data warehouse.
Updated over 3 years ago