What is Partitioning
A partitioned table is a special table that is divided into segments, called partitions, that make it easier to manage and query your data. By dividing a large table into smaller partitions, you can improve query performance, and you can control costs by reducing the number of bytes read by a query.
You can partition BigQuery tables by:
- Time-unit column: Tables are partitioned based on a
TIMESTAMP,DATE, orDATETIMEcolumn in the table. - Integer range: Tables are partitioned based on an integer column.
If a query uses a qualifying filter on the value of the partitioning column, only the partitions that match the filter will be scanned and the other partitions will be skipped. This process is called pruning.
Time-unit column partitioning
You can partition a table on a DATE,TIMESTAMP, or DATETIME column in the table. When you write data to the table, BigQuery automatically puts the data into the correct partition, based on the values in the column.
For TIMESTAMP and DATETIME columns, the partitions can have either hourly, daily, monthly, or yearly granularity. For DATE columns, the partitions can have daily, monthly, or yearly granularity. Partitions boundaries are based on UTC time.
For example, suppose that you partition a table on a DATETIME column with monthly partitioning. If you insert the following values into the table, the rows are written to the following partitions:
| Column value | Partition (monthly) |
|---|---|
DATETIME("2019-01-01") | 201901 |
DATETIME("2019-01-15") | 201901 |
DATETIME("2019-04-30") | 201904 |
In addition, two special partitions are created:
**NULL**: Contains rows withNULLvalues in the partitioning column.**UNPARTITIONED**: Contains rows where the value of the partitioning column is earlier than 1960-01-01 or later than 2159-12-31.
How to use Time-unit column partitioning in Y42
Using partitioning in Y42 it is as easy as one line of code at the end of your query.
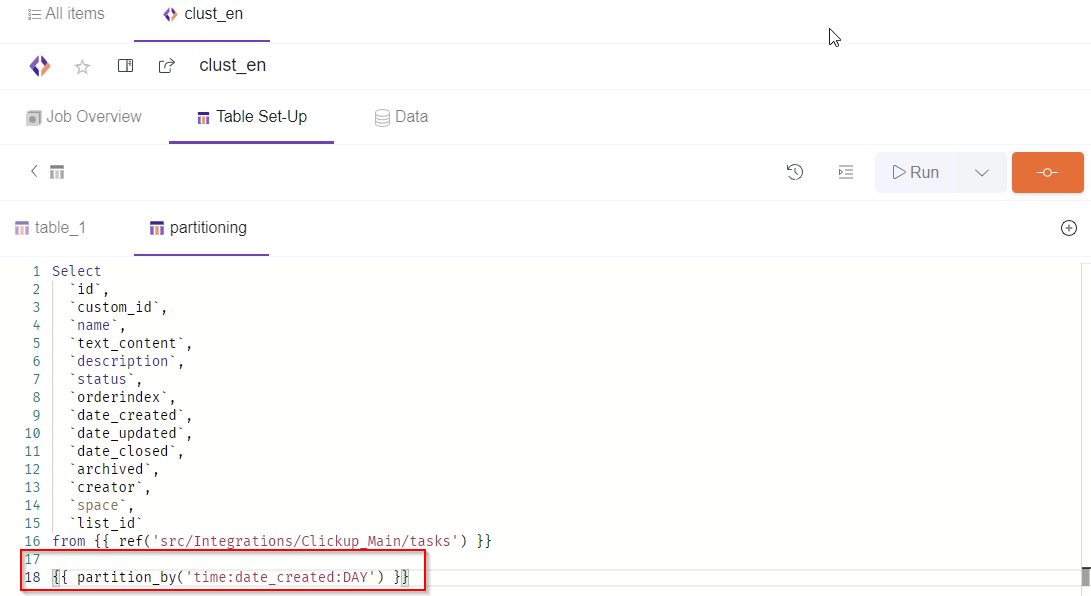
All you need to add at the end of your SQL Model query is a line of code specifying the type of partitioning, the column chosen for partitioning and the timeline measure (Hour, Day, Month, Year).
{{ partition_by('time:date_created:DAY') }}
The parameters to consider are:
- Type. In our case it is
timebecause we are partitioning on aTIMESTAMP,DATE, orDATETIMEcolumn in the table. - Column partitioned. Here we but the name of the column based on which we want to apply the partition condition.
- Timeline measure element. For
TIMESTAMPandDATETIMEcolumns, the partitions can have either hourly, daily, monthly, or yearly granularity. ForDATEcolumns, the partitions can have daily, monthly, or yearly granularity. Partitions boundaries are based on UTC time.
Partitioning changes the way your table is structured, that is why when you implement partitioning of clustering on your SQL model, you would have to run at least one full import on the SQL model initially for the changes to apply correctly.
Choose daily, hourly, monthly, or yearly partitioning.
When you partition a table by time-unit column or ingestion time, you choose whether the partitions have daily, hourly, monthly, or yearly granularity.
- Daily partitioning is the default partitioning type. Daily partitioning is a good choice when your data is spread out over a wide range of dates, or if data is continuously added over time.
- Choose hourly partitioning if your tables have a high volume of data that spans a short date range — typically less than six months of timestamp values. If you choose hourly partitioning, make sure the partition count stays within the partition limits.
- Choose monthly or yearly partitioning if your tables have a relatively small amount of data for each day, but span a wide date range. This option is also recommended if your workflow requires frequently updating or adding rows that span a wide date range (for example, more than 500 dates). In these scenarios, use monthly or yearly partitioning along with clustering on the partitioning column to achieve the best performance. For more information, see Partitioning versus clustering on this page.
Integer range partitioning
You can partition a table based on ranges of values in a specific INTEGER column. To create an integer-range partitioned table, you provide:
- The partitioning column.
- The starting value for range partitioning (inclusive).
- The ending value for range partitioning (exclusive).
- The interval of each range within the partition.
For example, suppose you create an integer range partition with the following specification:
| Argument | Value |
|---|---|
| column name | customer_id |
| start | 0 |
| end | 100 |
| interval | 10 |
The table is partitioned on the customer_id column into ranges of interval 10. The values 0 to 9 go into one partition, values 10 to 19 go into the next partition, etc., up to 99. Values outside this range go into a partition named **UNPARTITIONED**. Any rows where customer_id is NULL go into a partition named **NULL**.
How to use Integer Range Partitioning in Y42
Using partitioning in Y42 it is as easy as one line of code at the end of your query.
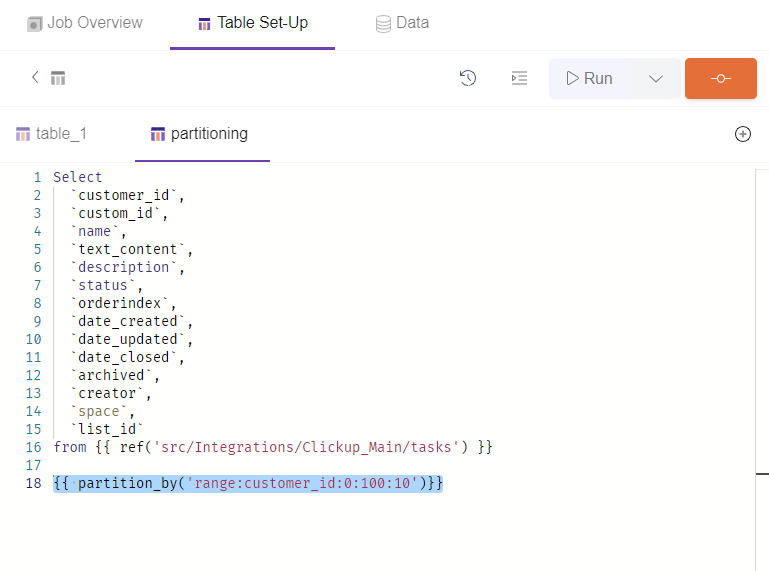
All you need to add at the end of your SQL Model query is a line of code specifying the column type of partitioning, the column chosen for partitioning and the ranges of values for the partitioned column.
{{ partition_by('range:customer_id:0:100:10')}}
The parameters to consider are:
- Type. In our case it is
rangebecause we are partitioning on an integer column. - Column partitioned. Here we but the name of the integer column based on which we want to apply the partition condition.
- Ranges of values.
Here we need to provide:
- The starting value for range partitioning (inclusive).
- The ending value for range partitioning (exclusive).
- The interval of each range within the partition.
Partitioning changes the way your table is structured, that is why when you implement partitioning of clustering on your SQL model, you would have to run at least one full import on the SQL model initially for the changes to apply correctly.
What is Clustering
When you create a clustered table in BigQuery, the table data is automatically organized based on the contents of one or more columns in the table’s schema. The columns you specify are used to colocate related data. When you cluster a table using multiple columns, the order of columns you specify is important. The order of the specified columns determines the sort order of the data.
Clustering can improve the performance of certain types of queries such as queries that use filter clauses and queries that aggregate data. When data is written to a clustered table by a query job or a load job, BigQuery sorts the data using the values in the clustering columns. These values are used to organize the data into multiple blocks in BigQuery storage. When you submit a query that contains a clause that filters data based on the clustering columns, BigQuery uses the sorted blocks to eliminate scans of unnecessary data.
You might not see a significant difference in query performance between a clustered and unclustered table if the table or partition is under 1 GB.
Similarly, when you submit a query that aggregates data based on the values in the clustering columns, performance is improved because the sorted blocks colocate rows with similar values
How to use Clustering in Y42
Using clustering in Y42 it is as easy as one line of code at the end of your query.
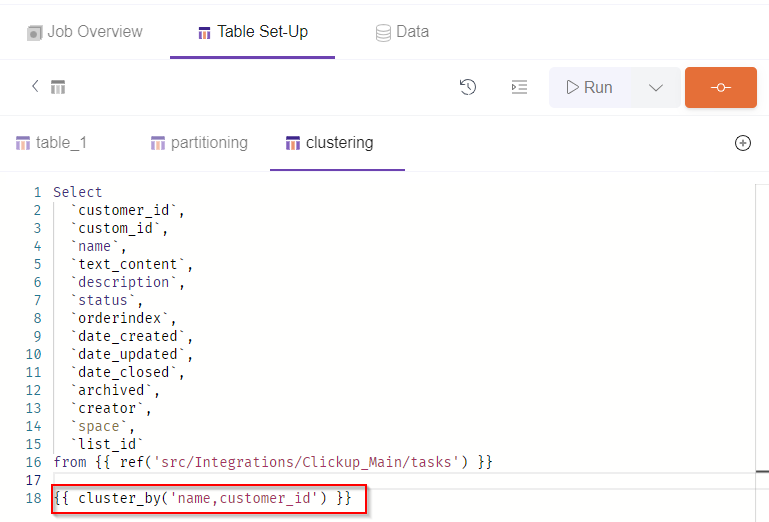
All you need to add at the end of your SQL Model query is a line of code specifying the columns chosen for clustering.
{{ cluster_by('name,customer_id') }}
Partitioning changes the way your table is structured, that is why when you implement partitioning of clustering on your SQL model, you would have to run at least one full import on the SQL model initially for the changes to apply correctly.
Partitioning versus clustering
Both partitioning and clustering can improve performance and reduce query cost.
Use clustering under the following circumstances:
- You don't need strict cost guarantees before running the query.
- You need more granularity than partitioning alone allows. To get clustering benefits in addition to partitioning benefits, you can use the same column for both partitioning and clustering.
- Your queries commonly use filters or aggregation against multiple particular columns.
- The cardinality of the number of values in a column or group of columns is large.
Use partitioning under the following circumstances:
- You want to know query costs before a query runs. Partition pruning is done before the query runs, so you can get the query cost after partitioning pruning through a dry run. Cluster pruning is done when the query runs, so the cost is known only after the query finishes.
- You need partition-level management. For example, you want to set a partition expiration time, load data to a specific partition, or delete partitions.
- You want to specify how the data is partitioned and what data is in each partition. For example, you want to define time granularity or define the ranges used to partition the table for integer range partitioning.
Prefer clustering over partitioning under the following circumstances:
- Partitioning results in a small amount of data per partition (approximately less than 1 GB).
- Partitioning results in a large number of partitions beyond the limits on partitioned tables.
- Partitioning results in your mutation operations modifying most partitions in the table frequently (for example, every few minutes).
You can also combine partitioning with clustering. Data is first partitioned and then data in each partition is clustered by the clustering columns.
When the table is queried, partitioning sets an upper bound of the query cost based on partition pruning. There might be other query cost savings when the query actually runs, because of cluster pruning.