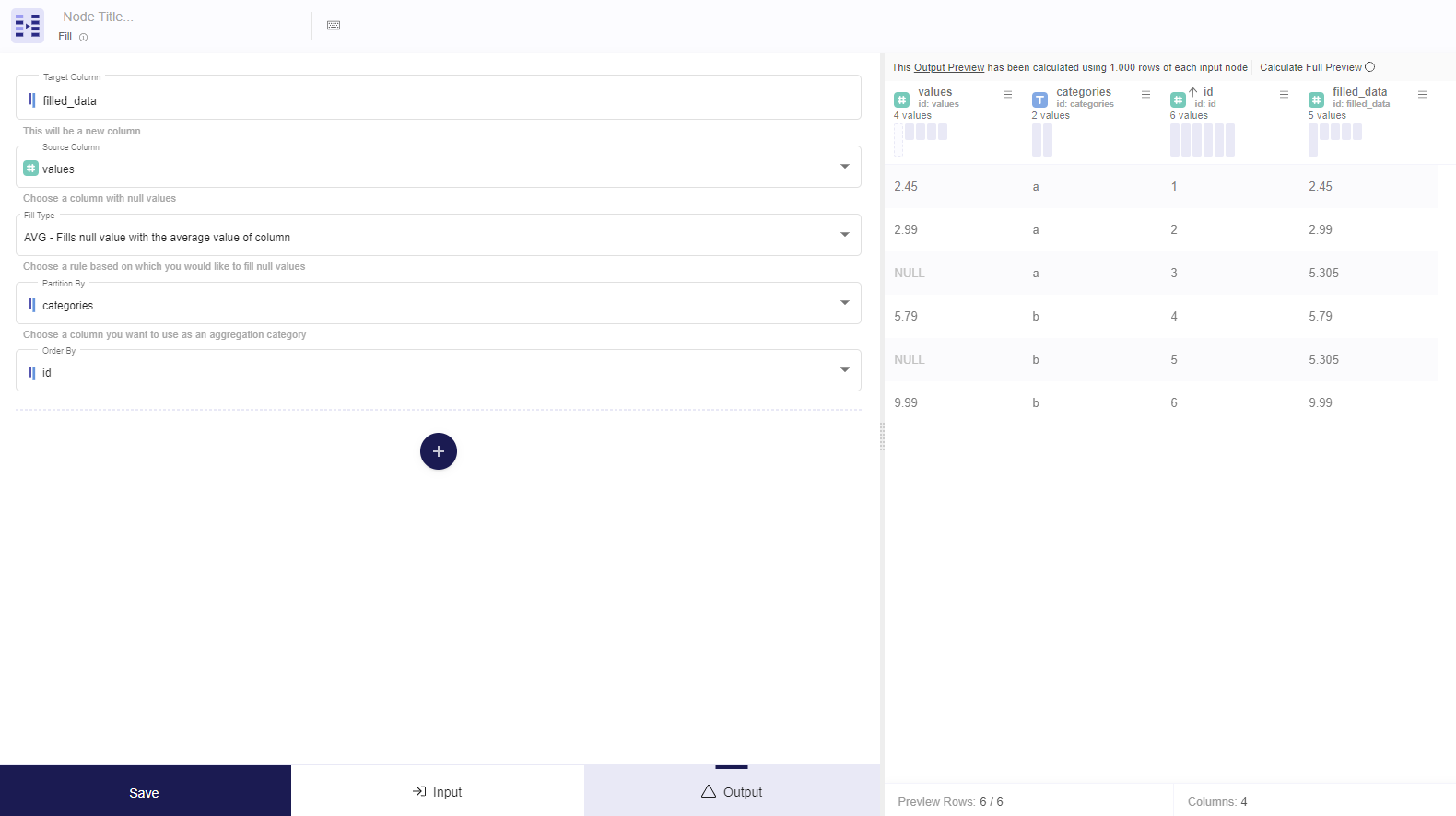
What is it used for
The Fill Node as its name suggests it is used to fill the empty (Null) value of the source column.
The user can decide the way it fills them, by choosing one of these functions:

What every function does is described in the description of each function, but we will get to it later below.
Functionality - What can it do
Lets assume we have these data input here:
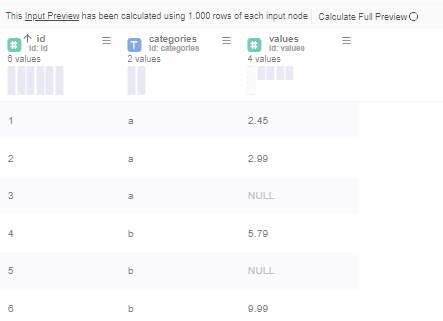
As you can see we have 2 Null values for id 3 and 5.
For special purposes we do not need those null values and we want to Fill them programmatic ally.
We could try to fill them with the first not Null value (FIRST_VALUE function) of the Category by partitioning the data into categories and ordering by ID
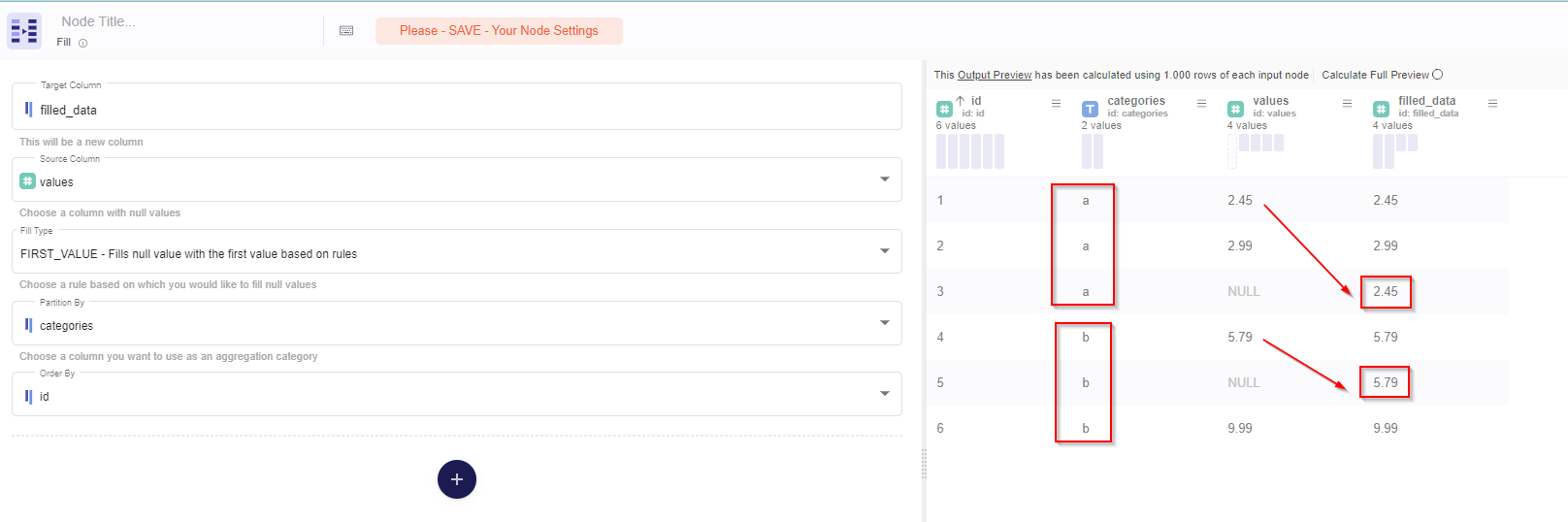
As you can see we just replaced Null with he first value of its category partition.
We can apply the same filling logic we did with FIRST_VALUE function with the following functions:
- LAST_VALUE function → replaces Null with the last non Null value in its Partition
- NTH_VALUE function → replaces Null with the Nth non Null value in its Partition
- NTH_VALUE function → replaces Null with the Average non Null value in its Partition
- CONSTANT function → replaces Null with a Constant value you choose. (For example you could replace NULL with 0 or any value)
How to set it up
In order to set it Up the user must Connect the Fill node with any Node:
Then open the Fill node and do the following:
1- Define the Target Column. If the user wants the data to appear in a new column he/she should type a the new column name. Otherwise the user can choose to place the filled data into an existing column by selecting that column as the target Column.
2- Select the Source Column. This should be the column that contains the NULL values.
3- Select Fill Type function. Here the user selects the criteria **** by which the NULL values is going to be filled.
One of the following functions should be selected:

4- Select the Partition By Column/s. (Optional)
This step is optional. Here we can group by an other column's values, as in our example by categories which had values "a", "b". If we choose to not partition the data all the set of data will be taken as it is without being grouped.
5- Select the Order By Column/s. (Optional)
This step is optional. Here we can order the data set by a desired column's values (as in our example by ID ascending). If we choose to not order the data the order of the data set will be taken as it is.
Note: Please take into consideration that steps 4 and 5 are important for choosing the right value (having control) you want to fill NULL with.
If you choose to Fill with Constant there is no point of doing step 4 and 5 because the result will be the same even if you don't do these steps.